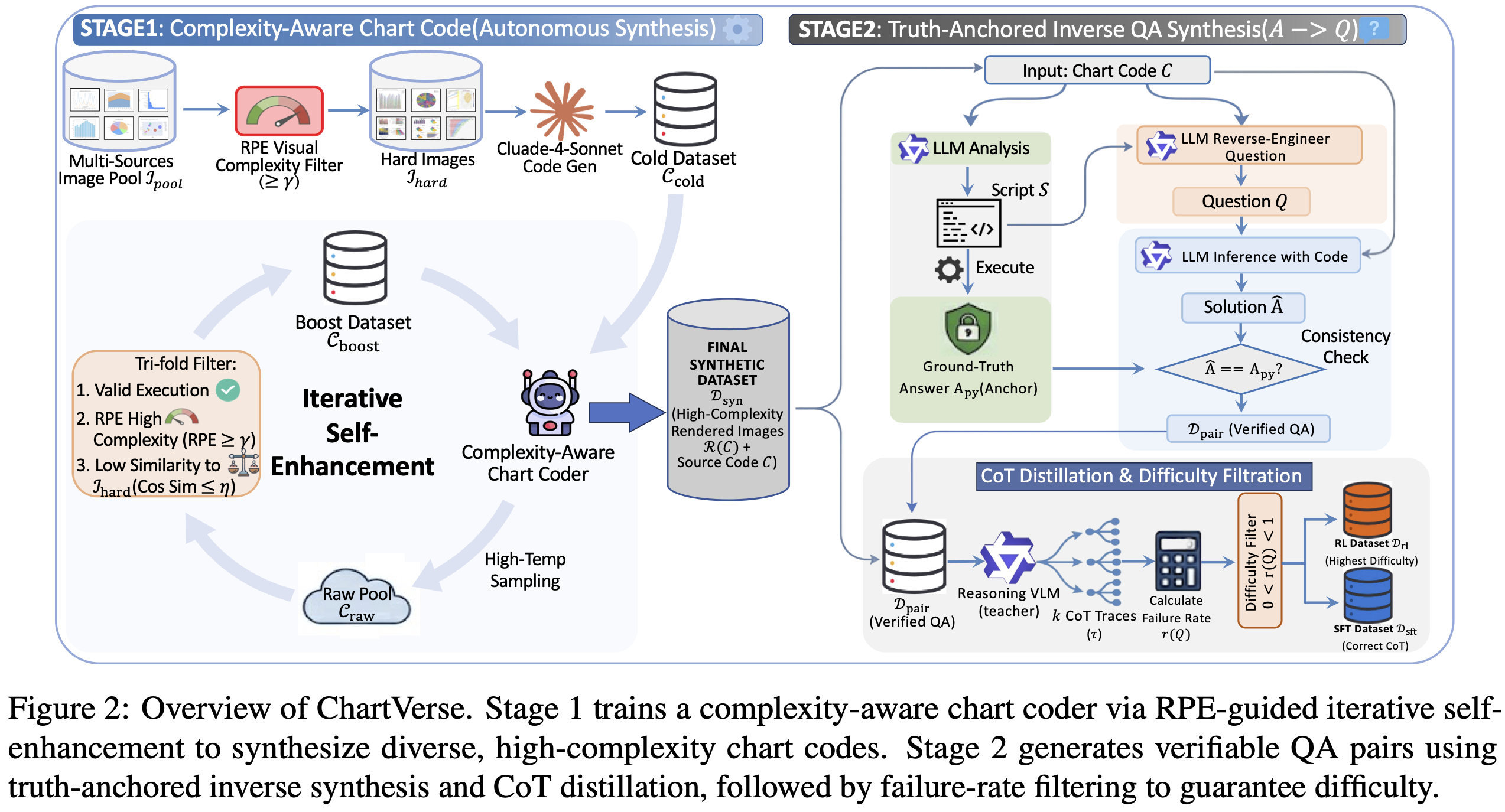
Methodology
A two-stage framework combining complexity-aware chart synthesis with truth-anchored QA generation
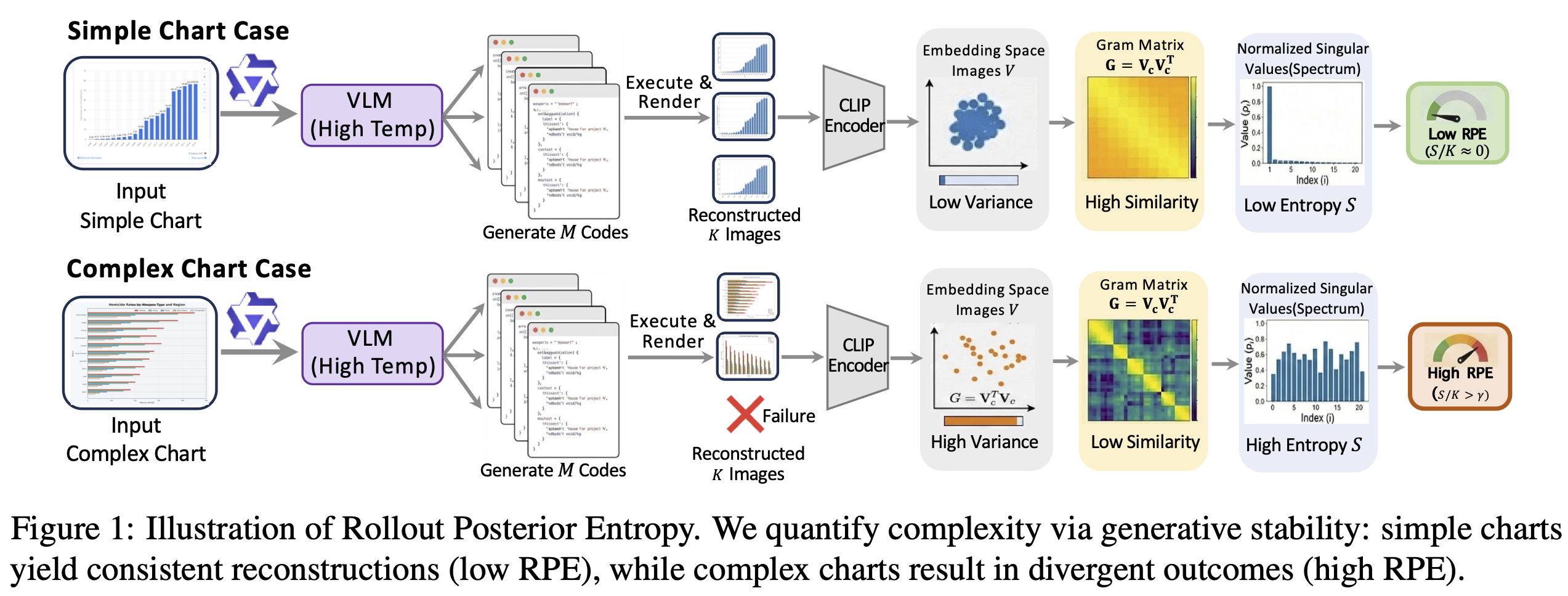
1. Rollout Posterior Entropy
Given a chart, we prompt a VLM to generate executable code 8 times. Simple charts yield consistent codes, while complex ones lead to divergence. We compute spectral entropy from CLIP embeddings, retaining samples with RPE ≥ 0.4.
2. Complexity-Aware Coder
We train a specialized coder via iterative self-enhancement. Starting from a cold-start dataset filtered by high RPE, we repeatedly generate, filter by complexity and similarity, and retrain to produce diverse charts from scratch.
3. Truth-Anchored Inverse QA
We invert the generation flow: first extract deterministic answers from code execution, then reverse-engineer questions. A consistency check ensures logical soundness. Failure-rate filtering retains challenging samples.